t_flm电影表(100万行)
创建数据库:
DROP TABLE IF EXISTS t_film;
CREATE TABLE t_film(
id INTEGER AUTO_INCREMENT PRIMARY KEY,
score DECIMAL(2,1) NOT NULL COMMENT ‘评分’,
release_date DATE NOT NULL COMMENT ‘发行日期’,
film_name VARCHAR(20) NOT NULL COMMENT ‘电影名称’,
introduction VARCHAR(30) NOT NULL COMMENT ‘简介’
);
创建1000000条测试数据:
#删除存储过程
DROP PROCEDURE IF EXISTS proc_t_film;
#创建存储过程
DELIMITER $$
CREATE PROCEDURE proc_t_film(total int)
BEGIN DECLARE 1 INTEGER DEFAULT 1;
START TRANSACTION;
WHILE i<=total
DO INSERT INTO t_fi1m(score, release_date, fi1m_name, introduction)
VALUES (
ROUND(RAND() * 9.9, 1),
DATE_ADD(NOW(),
INTERVAL FLOOR(RAND() * 10000) DAY),
CONCAT(‘fi1m_name’, 1),
CONCAT(‘introduction’, i) );
SET =1 + 1;
END WHILE;
COMNIT;
END $$
DELIMITER ;
#执行存储过程
CALL proc_t_fi1m(1000000);
测试数据内容如下:
id score release_date fim_name introduction 1 4.9 2028-11-29 fim_name1 introduction1 2 5.6 2027-12-02 fim_name2 introduction2 3 1.8 2034-05-21 fim_name3 introduction3
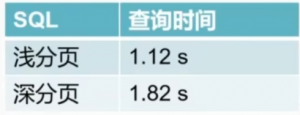
查询要求:查询电影表中第N页数据,每页20条记录,按照评分降序进行排序, 查询字段为评分(score) , 发行日期(release_date) ,电影名称(film_name):
浅分表
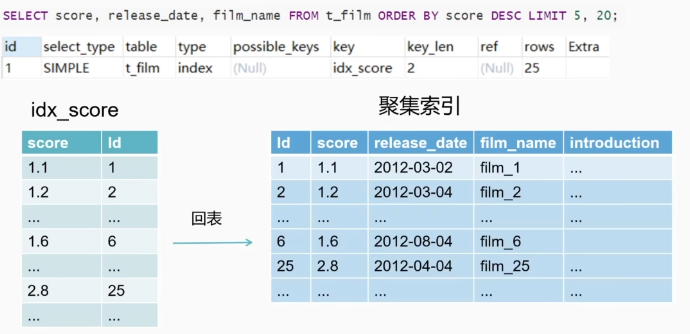
SELECT score, release_date, fi1m_name FROM t_fi1m ORDER BY score DESC LIMIT 5, 20;
深分表
SELECT score, release_date, fi1m_name FROM t_fi1m ORDER BY score DESC LIMIT 90000, 20;
explain分析:
![]()
优化1:索引
Order By字段加单列索引
$ ALTER TABLE t_film ADD INDEX idx_score (score);
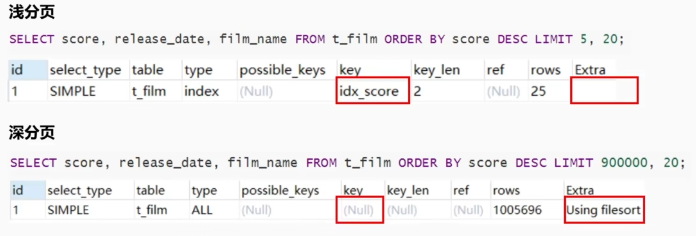

从执行效果上可以看出,浅分页得到了一个优化,而对于深分页来说基本没有效果。
原因分析:
“type=index”。说明是“全索引扫描”。
“LIMIT 5,20”,将会扫描25行数据,接着丢弃掉前5条,根据保留的20条数据。然后[回表查询]“release_date”、“fi1m_name”的最终结果。
这时候回表的成本将>自己排序的成本。优化器会选择不走索引。
深分表(强制走索引)
SELECT score, release_date, fi1m_name FROM t_fi1m force index(idx_score) ORDER BY score DESC LIMIT 90000, 20;
在测试过程中发现,当迁移量在4000-5000之前,mysql都会走索引,超出就走全表扫描。
优化2:解决深分页问题
方法一: Order By和Select字段加联合索引
ALTER TABLE t_film ADD INDEX idx_score_date_name (score, release_date, film_name);
注意:score要在首位

走索引消除了Using Filesort,并使用了覆盖索引

方法二: Order By字段加索引并手动回表
SELECT score, release_date,film_name FROM t_film a join,
(SELECT id FROM t_ fi1m ORDER BY score DESC LIMIT 900000,20)b on a.id = b.id;
![]()

对比方法一:
●不需要添加联合索引
●不会随着查询字段的增加而影响性能
手动回表的应用一解决由于回表性能消耗过大而不走索引的问题
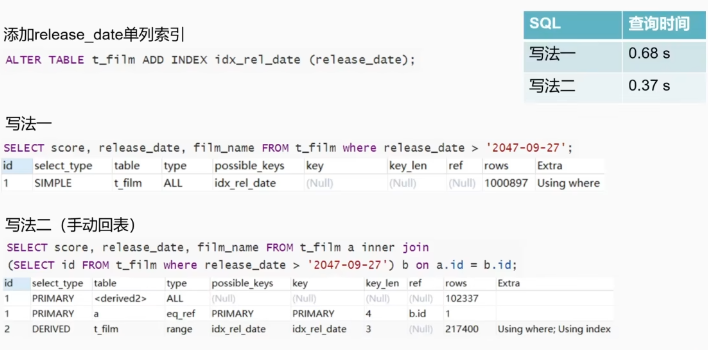
注意:当子查询结果集太大时,手动回表的性能反而比不上全查询
参考视频:https://www.bilibili.com/video/BV198411F7hx/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=3790692eb971db4659c7e5f6dc3e29fc