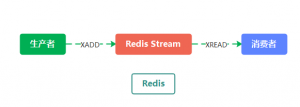
模型1(把 List 当作队列)
Redis List 底层的实现就是一个「链表」,在头部和尾部操作元素,时间复杂度都是 O(1),这意味着它非常符合消息队列的模型。
1.生产者使用 LPUSH 发布消息:
127.0.0.1:6379> LPUSH queue msg1 (integer) 1 127.0.0.1:6379> LPUSH queue msg2 (integer) 2
2.消费者使用 RPOP 拉取消息:
127.0.0.1:6379> RPOP queue "msg1" 127.0.0.1:6379> RPOP queue "msg2"
这个模型非常简单,也很容易理解。
小问题:当队列中已经没有消息了,消费者在执行 RPOP 时,会返回 NULL。
127.0.0.1:6379> RPOP queue (nil) // 没消息了
php端代码逻辑:
while true:
msg = redis.rpop("queue")
// 没有消息,继续循环
if msg == null:
continue
// 处理消息
handle(msg)
模型缺点:
如果此时队列为空,那消费者依旧会频繁拉取消息,这会造成「CPU 空转」,不仅浪费 CPU 资源,还会对 Redis 造成压力。
模型优化1:当队列为空时,我们可以「休眠」一会,再去尝试拉取消息。
while true:
msg = redis.rpop("queue")
// 没有消息,休眠15s
if msg == null:
sleep(15)
continue
// 处理消息
handle(msg)
模型优化1缺点:当消费者在休眠等待时,有新消息来了,那消费者处理新消息就会存在「延迟」。
假设设置的休眠时间是1 5s,那新消息最多存在1 5s 的延迟。要想缩短这个延迟,只能减小休眠的时间。但休眠时间越小,又有可能引发 CPU 空转问题…
模型优化2:如果队列为空,消费者在拉取消息时就「阻塞等待」,一旦有新消息过来,就通知我的消费者立即处理新消息呢?这样既能及时处理新消息,还能避免 CPU 空转。
模型2(阻塞等待)
「阻塞式」拉取消息的命令:BRPOP / BLPOP,这里的 B 指的是阻塞(Block)。

php端代码逻辑:
while true:
// 沒有消息阻塞等待,0表示不设置超时时间
msg = redis.brpop("queue", 0)
if msg == null:
continue
// 处理消息
handle(msg)
使用 BRPOP 这种阻塞式方式拉取消息时,还支持传入一个「超时时间」,如果设置为 0,则表示不设置超时,直到有新消息才返回,否则会在指定的超时时间后返回 NULL。
注意:如果设置的超时时间太长,这个连接太久没有活跃过,可能会被 Redis Server 判定为无效连接,之后 Redis Server 会强制把这个客户端踢下线。所以,采用这种方案,客户端要有重连机制。
模型优点:兼顾效率,避免CPU空转
模型缺点:
1.不支持重复消费
消费者拉取消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费,
即不支持多个消费者消费同一批数据
2.消息丢失
消费者拉取到消息后,如果发生异常宕机,那这条消息就丢失了。
因为从 List 中 POP 一条消息出来后,这条消息就会立即从链表中删除了。
也就是说,无论消费者是否处理成功,这条消息都没办法再次消费了。
模式3(发布/订阅模型:Pub/Sub)
发布、订阅的命令: PUBLISH / SUBSCRIBE (多组生产者、消费者的场景)
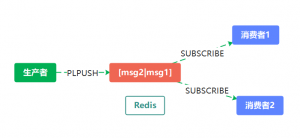
注意:消费者必须先订阅队列,生产者才能发布消息,否则消息会丢失。
1.使用 SUBSCRIBE 命令,启动 2 个消费者,并「订阅」同一个队列:
127.0.0.1:6379> SUBSCRIBE queue Reading messages...(press Ctrl-C to quit) 1) "subscribe" 2) "queue" 3) (integer) 1
此时,2 个消费者都会被阻塞住,等待新消息的到来。
2.启动一个生产者,发布一条消息:
127.0.0.1:6379> PUBLISH queue msg1 (integer) 1
这时,2 个消费者就会解除阻塞,收到生产者发来的新消息。
127.0.0.1:6379> SUBSCRIBE queue Reading messages...(press Ctrl-C to quit) // 收到消息 1) "message" 2) "queue" 3) "msg1"
模型优点:支持发布/订阅,支持多组生产者、消费者处理消息
模型缺点:消息丢失
Pub/Sub 在实现时非常简单,它没有基于任何数据类型,也没有做任何的数据存储,它只是单纯地为生产者、消费者建立「数据转发通道」,把符合规则的数据,从一端转发到另一端。
如果发生以下场景,就有可能导致数据丢失:
1.消费者下线
如果一个或多个消费者异常挂掉了,它再重新上线后,只能接收新的消息,在下线期间生产者发布的消息,因为找不到消费者,都会被丢弃掉。
2.Redis宕机
因为 Pub/Sub 没有基于任何数据类型实现,所以它也不具备「数据持久化」的能力。当 Redis 宕机重启,Pub/Sub 的数据也会全部丢失。
3.消息堆积
每个消费者订阅一个队列时,Redis 都会在 Server 上给这个消费者在分配一个「缓冲区」,这个缓冲区其实就是一块内存。
当生产者发布消息时,Redis 先把消息写到对应消费者的缓冲区中。之后,消费者不断地从缓冲区读取消息,处理消息。
因为这个缓冲区其实是有「上限」的(可配置),如果消费者拉取消息很慢,就会造成生产者发布到缓冲区的消息开始积压,缓冲区内存持续增长。
如果超过了缓冲区配置的上限,此时,Redis 就会「强制」把这个消费者踢下线。
模式4(Stream)[最优解决]
首先,Stream 通过 XADD 和 XREAD 完成最简单的生产、消费模型:
* XADD 发布消息
* XREAD 读取消息
1.生产者使用XADD 发布消息:
// [*] 表示让Redis自动生成唯一的消息ID 格式:[时间戳-自增序号]
127.0.0.1:6379> XADD queue * msg1 hello
"1624873347-0"
127.0.0.1:6379> XADD queue * msg2 world
"1624930713-0"
2.消费者使用XREAD 拉取消息:
127.0.0.1:6379>XREAD COUNT 10 STREAMS queue 0-0
1) 1) "queue"
2) 1) 1) "1624873347-0"
2) 1) "msg1"
2) "hello"
2) 1) "1624873347-0"
2) 1) "msg2"
2) "world
如果想继续拉取消息,需要传入上一条消息的 ID:
此处已经没有消息,Redis 会返回 NULL。
127.0.0.1:6379>XREAD COUNT 10 STREAMS queue 1624873347-0 (nil)